|
|
Tech Note 02a: PDB File StructureMay 01, 2008© NSB Corporation. All rights reserved. |
| PDB files do not have a not a difficult structure
to understand and figure out with the correct tools. Once you
know this structure, you can easily make pdb files using VB or
other tools. In this short Tech note, I'll explain the structure of the most simple PDB file. Once you understand this, you will be able to understand other, more advanced cases more easily. Getting Started We will
be using a Non-keyed file in NS Basic/Symbian OS. Dim Db as Database
Dim res as Integer
res=DbCreate(Db,"DB-CREATE-TEST",0,"Test") 'Creator ID is "Test"
If res=0 then 'Created successfully
res=DbOpen(Db,"DB-CREATE-TEST",0)
res=DbPosition(Db,1,0) 'Position pointer to record 1
res=DbPut(Db,"NS BASIC") 'Write it
res=DbPosition(Db,2,0) 'Position pointer to record 2
res=DbPut(Db,"mizuno-ami")
res=DbPosition(Db,3,0)
res=DbPut(Db,"Simple Sample")
res=DbClose(Db)
End if
Reading the file can be done through this code:(Field1008 shows the data which specified record at Field1006.) Dim Db as Database
Dim res as Integer
Dim intSet as Integer
Dim strData as String
intSet=Val(Field1006.Text)
res=DbOpen(Db,"DB-CREATE-TEST",0)
res=DbPosition(Db,intSet,0) 'Position pointer to the value in field1006
res=DbGet(Db,strData)
res=DbClose(Db)
Field1008.text=strData 'Display your db data
After inputting this code into a sample project, you can create a sample
file.After compiling, and running the program, create a file by clicking on "Create". Now, move the file to the desktop using the Nokia PC Suite's File Manager. Select the file we created, called "DB-CREAT-TEST", and export it to a location that we can easily find (the desktop). To check to ensure the file has been made correctly, type in "1" in the "Record" field and then read. We created 3 records. 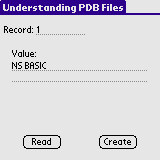
To see the "inside" of the PDB file you will need a hex editor. I will be using Hex Workshop 3.11 (actually another hex editor is shown, but Hex Workshop works well for this purpose), but any hex or binary editor will do. 
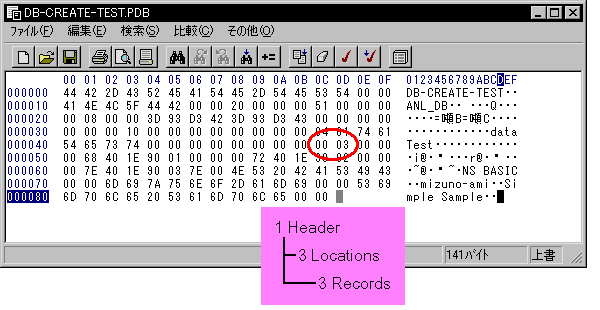
A PDB file is split up into 3 sections:
The Header Let's look at the File header.
Let's look up these data in order. The file name is typically 32 byte data, followed by a null terminator "00" (Each field we see will be terminated by null). In most cases, you will find other unusal strings (like "ANL") after the null that you did not write. This is perfectly normal, depending on how the file was made. Data after "00" is ignored.  The next 2 bytes, you can find "00 08", this is the attribute of the file. Usually, you must manually set this flag "00 08". The next 2 bytes, is the version number. In our example, "00 00" is written here, so our version number is the decimal equivalent of "00 00" hex, also "0". The next bit of information is the create time, the modify time and the backup time, all measured in seconds data (4 bytes) Time is measured in seconds since '1904-01-01 00:00:00'. We won't have to worry about this, so we'll skip it here. You can find ample information on the internet about this if you wish. Backup time is not updated automatically.  The next bit of data is the 'modification number' a number that counts the numbe rof times a modification has been done. When you will make a new PDB file, you can write "00 00 00 00" it. The application info size and sort info size, is also something we need not worry about. For our case, this is "00 00 00 00", simply meaning that this information is not present. The simplest files do not need this information. The next 2 bytes of data may be familiar to you. The first 4 bytes is file type and next 4 bytes is creator ID. As a file , the type will be usually "data". The creator ID will be set by you when you create this file file using DbCreate(). In our example case, "Test". 
Next 8 bytes , I don't know in detail but I know these are not needed for our purpose. The last 2 bytes of header is number of records. Records we wrote are 3 records, and so here is "00 03".(written in hex) The data here is 2 bytes, meaning that the maximum number of records is 65535 records. 
Those are the basic details of the header data of 78 bytes. Location information (Record Header - "Table of Contents") After the header, we must know what record to lookup and where to look it up. A technique very similar to a book's table of contents is used. After knowing what "chapter" to look up, you go to the table of contents to look up the page number and then go quickly to the page number. Can you skip the TOC and go directly to the page? Sure you can, if you know where it is, otherwise you must scan each page for the information you want. This is very slow. It is slow in NS Basic as well. In our example of 3 records, we should have a table of contents with 3 entries (records)in it and 3 page numbers (locations)
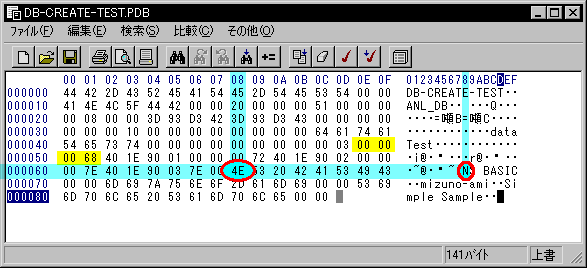
It may be helpful for you to understand that this is an index. Let's start from the beginning. After the header (78bytes) we are at position 78 or in hex 4E. The next four bytes are the location information for the first record number. Reading in the four bytes, we get 00 00 00 68 (hex). This is the address of the first record in our file. If we go to address 68 (the leading zeros drop off), we find our first record, "NS BASIC". If we want the second record, we read our next table of contents entry starting 4 bytes after our location of record 1 (note, each TOC entry is 8 bytes, so from byte 78, we would skip the first 8 bytes (rec#1) and then read at offset 78+8=86 dec or 56 hex which would read the beginning of record #2 (mizuno...)
Once we know the structure of the PDB header, we can theoretically find
any record number we want. All we have to do is a simple calculation
and read the table of contents. How? As an example in this case,
to read the 3rd record, the header is 78 byte, so 78 + 3 * 8 = 102 -> 066H, is the
start of record #3's real data
location. This tutorial was originally made by mizuno-ami and then modified/translated/cleaned up by Jeff VanderWal. |